Cloud service providers like AWS are changing the way developers build applications, and there's a lot to know about how they work behind the scenes. The funny thing is I've worked with two different teams where all of our production applications ran on AWS, but someone else always managed them so I never felt much of an urgency to learn more about it.
I think this is a pretty common situation in general among junior to mid-level engineers, where your project is managed by dedicated devOps engineer(s) and/or your lead engineer. This is great for the business because it allows developers to focus on coding, but not so great for the developers who won't get experience with the management console, configurations, CI/CD pipeline, etc unless someone hosts a knowledge share.
Adding to this conundrum are services like Vercel and Netlify which use AWS under the hood, further abstracting all of the usual infrastructure concerns. These services are great in that they remove many barriers involved with deploying an application on AWS, but that convenience comes with a modest fee and offers less flexibility with regard to the underlying AWS services.
This is fine for developers who want to focus only on the application and not the infrastructure, but it does seem like a lost opportunity to not only gain knowledge but also optimize for cost. Last week I officially obtained my first AWS certification, so now I'm much more aware of the available services and different opportunities to optimize, so let's get into it!
Fair warning, this will get heavy when we get into my DynamoDB schema, since it won't make sense without talking about the technicals of its core components.
Cost optimization is one of the 6 pillars of the AWS Well-Architected Framework and for good reason. Cloud services are all about pay-as-you-go pricing, which means it's up to you to choose the most cost-effective services for your solution.
As I explained in my first blog post, I originally chose RDS because I have the most experience with relational databases, and it was the easiest option to implement with SST. However, what I didn't realize is that RDS with Aurora Serverless v1 is only serverless in that it automatically scales Aurora Capacity Units (ACUs) based on the application workload.
Other than that, if you want to use such a database in production, you'll have to pay for a minimum of 2 ACUs at $0.06 per hour, all day, every day which amounts to $87.60 per month, holy moly!
At this point I had to decide whether my desire to work with a relational database was worth the cost. One option was a full EC2-based rewrite of the application (without SST), another was switching to Vercel, but the option providing the most cost savings with the lowest effort, and while maintaining control of my AWS environment, seemed to be DynamoDB, especially thanks to it being part of the AWS Always Free Tier.
One of the best things about DynamDB is that it's truly serverless meaning that you don't need to manage the underlying instances or infrastructure powering it. DynamoDB is always running and ready to handle as many requests as can conceivably be thrown at it, so you don't need to worry about cold starts or pausing and resuming a DB cluster like with RDS.
Breaking down my new AWS bill, since my application uses only Free Tier services including S3, Lambda, and SQS, eliminating my only significant cost in RDS would allow running my application for basically free and with solid rate limits compared to Vercel's Hobby Plan. Looking at Vercel's plans, again the issue with Postgres is the number of hours the instance needs to be running, which in production needs to be 24/7 unless one wants to work around cold starts.
With the hobby plan you only get 60 free hours, and even with the Pro plan you only get 100 included hours, with every hour after that costing $0.10. In production you'll exceed those limits in less than a week, and that's not even including paying for ACUs as needed for dev and staging environments.
Now that I have some experience using a managed Postgres database in production, I have a hard time imagining how this could be a cost-effective solution compared to an optimized EC2 architecture where you only pay for exactly what you use.
I want to preface this by saying that this is the first time I've ever worked with a NoSQL database, so there's a good chance that my new schema is not perfectly optimal, but without further ado let's dive into it.
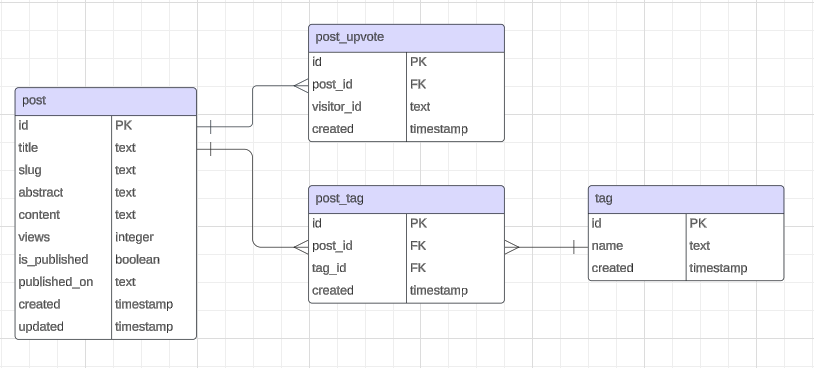
Before:
After:

NoSQL differs from relational database management systems (RDBMS) in that you design your schema to make the most common and important queries as fast and as inexpensive as possible, instead of creating a normalized data model without thinking about access patterns. In my case I only have four queries: get published posts, get all tags, get all published posts that have a particular tag, and get a post by its slug.
One key concept for NoSQL design according to AWS is maintaining as few tables as possible to keep things more scalable, have less permissions management, and reduce overhead for the application. That said, first I did away with the whole PostUpvote table in favor of a likes key-value pair directly on the Post table in the spirit of simplification. Second, the PostTag junction table had to go in order to begin denormalizing the data, and then finish by adding a tags attribute to the Post table.
The biggest shift coming from any RDBMS is that DynamoDB stores data in partitions which are allocations of storage for a table, backed by solid state drives (SSDs). The primary key uniquely identifies each item in a DynamoDB table similar to the id of a row in SQL, but with some key differences. It is the fastest way to retrieve an item and can be simple (a partition key only) or composite (a partition key combined with a sort key).
Unfortunately, the efficiency of partitions comes with a price in that the only way to directly get item(s) is by using the primary key, although you can always use a FilterExpression to filter by any attribute. Essentially, you can get multiple copies of the same item from a table or index, but if you want to get different items without scanning the whole table you'll need to create a Global Secondary Index (GSI) which lets you query data using an alternate key. I like to think of GSIs as a way to group different items together in ways that my data access patterns call for.
GSI's allow more flexibility when querying data and open up some interesting possibilities. DynamoDB maintains indexes automatically, so when you change an item in the base table, it makes the same change to the correspending item in all of the indexes.
So, I created a GSI with a partition key representing the publish status of a post and a sort key that is the publish date. This lets me query the index where posts are partitioned by publish status, and automatically sorted in numerical order, which is exactly what I needed.
It's strange to me that the only example of a use case for a sort key given by the documentation is for version control. This seems like the most obvious example because a sort key can only operate on items with the same partition key, but you can still implement index(es) to make use of it by grouping items based on your access patterns.
Anyway, since NoSQL requires designing the schema to be optimized for data access patterns, writing the queries themselves was pretty straightforward so I think this is a good place to leave off.
Evaluating tradeoffs is a huge part of the software development lifecycle, and as engineers it's something we do constantly. It's about prioritizing what is most important to you, your team, and/or your business.
Sometimes you have to make an uncomfortable decision, one that gives you no choice but to learn something new in order to satisfy a higher priority like cost optimization in my case.
It's a blessing in disguise really, because although it may take more time to implement than expected, ideally the top priority was achieved and new knowledge is gained, and as we know, knowledge is power. Until next time, happy coding!
April 19, 2024